Val Vibes: Semantic search in Val Town
If you’ve been following along, you know that code search is hard. Matching a search query to a particular val, allowing for misspellings, adding ranking signals to prioritize the best content, is a complicated and error-prone quest.
But what if it wasn’t? Instead of parsing code to extract terms and creating inverted indexes for trigrams, what if we used vibes to search?
Similar vibes
“Search” is about finding documents based on a query, using some sort of sorting mechanism that ranks the most relevant documents. You might rank a document higher if it contains the search term more often, or prioritize documents with an exact match over those that only roughly match the search term.
We’ll look at a completely different sorting mechanism called “semantic search”, which uses one of those crazy features to come out of the world of machine learning: embeddings. It works like this: you put in a string into an API, and you get an array of numbers, called an “embedding”, with the property that things that have the same “vibe” will get similar numbers.
For example, “animal that barks” should have similar vibes to “dog”. And “dog bites man” should have different vibes than “man bites dog”. And “discord bot” should have very different vibes still.

Solid bite.
So we need to generate an embedding when a document is created or updated. Then, when someone searches for something, we create an embedding for their search query. Then we find the document embeddings that are closest to the query embedding.
That’s the idea, though in practice embeddings can be quite unpredictable and surprising. Our examples above already break down… “animal that barks” vibes more with “woof woof woof” than with “dog”. And “dog bites man” and “man bites dog” have even more similar vibes than that, presumably because there’s lots of biting going on in both cases.
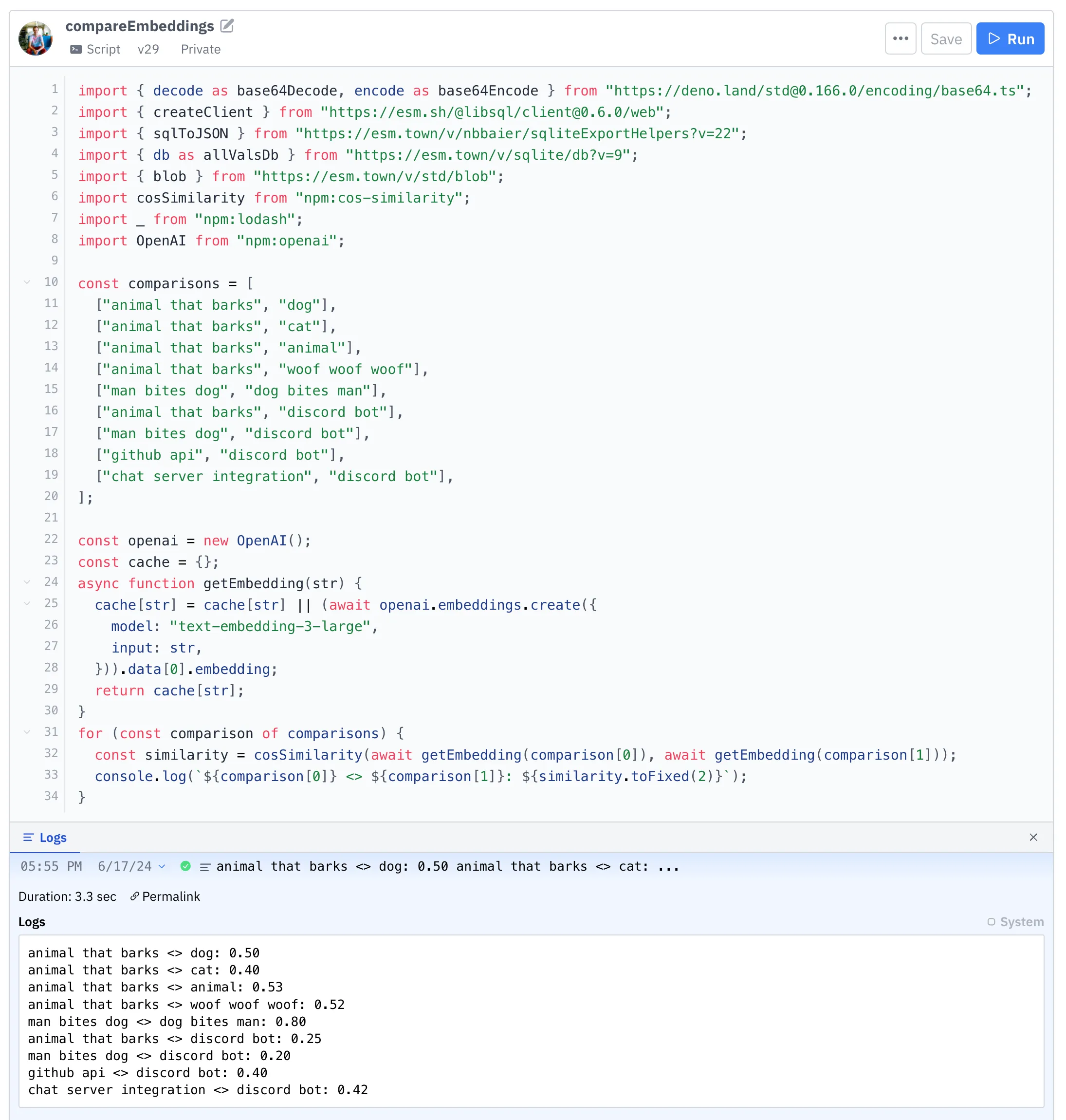
Woof woof woof.
For our purposes though, embedding similarity is high between “discord bot” and “github api”, or “chat server integration”. This helps in finding code that is not exactly the same, but still relevant to the search query.
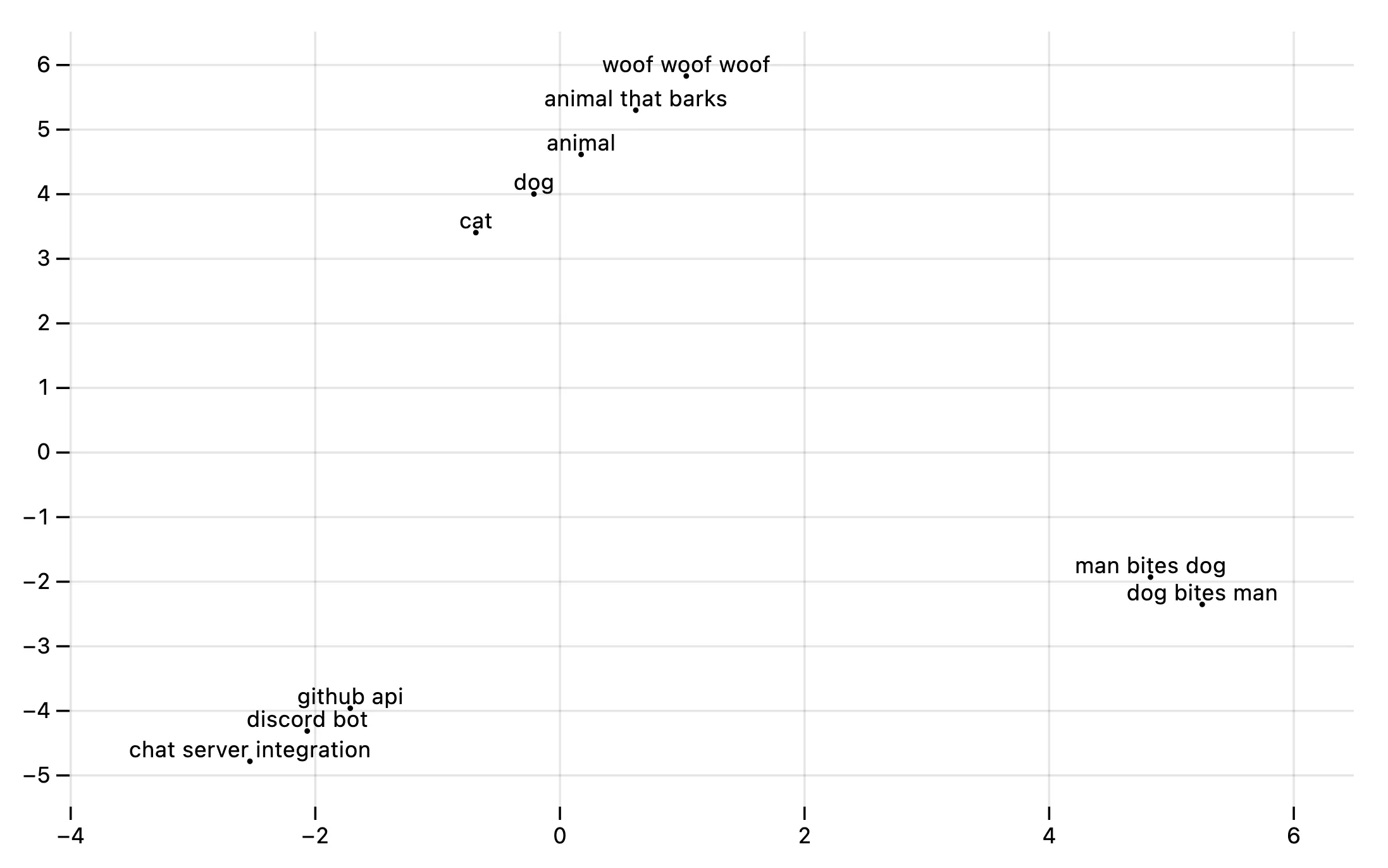
Similar vibes, plotted by this val.
Prototyping in Val Town
I started prototyping this on my computer, but then realized: this is Val Town, the ultimate prototyping tool for things like this. I ended up making three different semantic search vals, using different storage engines: Postgres (using Neon), SQLite (using Turso), and in-memory (using blob storage). Let’s look at Postgres first, and at the end I’ll also show how to do this in-memory.
There are two phases to semantic search:
- Indexing: generating embeddings for all public vals.
- Querying: generating an embedding for the search query, and comparing to the indexed embeddings.
For indexing, we first create a Postgres table on Neon (using the pgvector extension):
CREATE TABLE vals_embeddings (id TEXT PRIMARY KEY, embedding VECTOR(1536));Then we create a cron val (or as I like to call them: inter-val…), which we set to run every hour.
First we query all vals, for which Achille Lacoin had already made an excellent val:
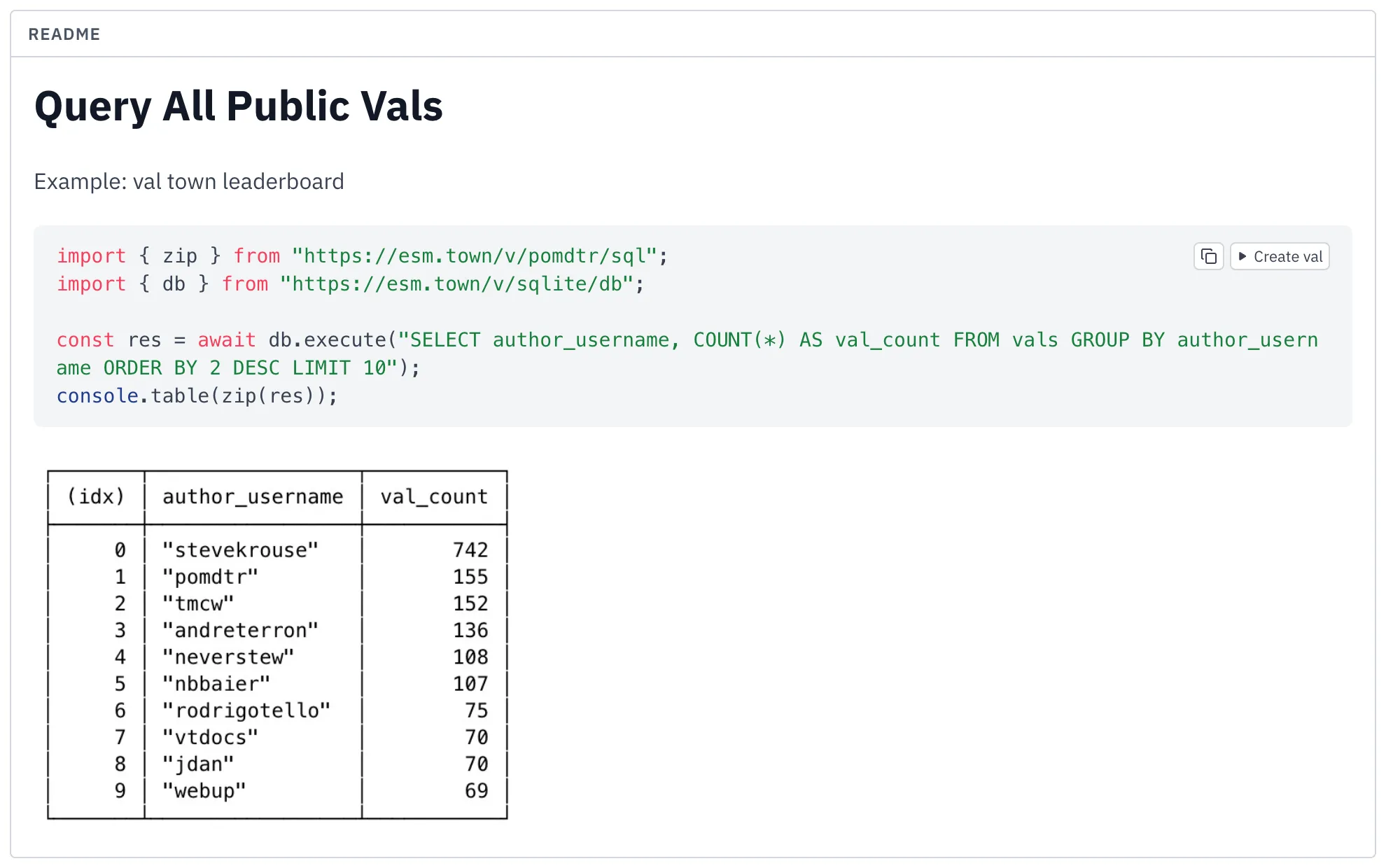
Querying public vals, by Achille Lacoin.
We filter out vals for which we have existing embeddings, put the rest in batches of 100 vals.
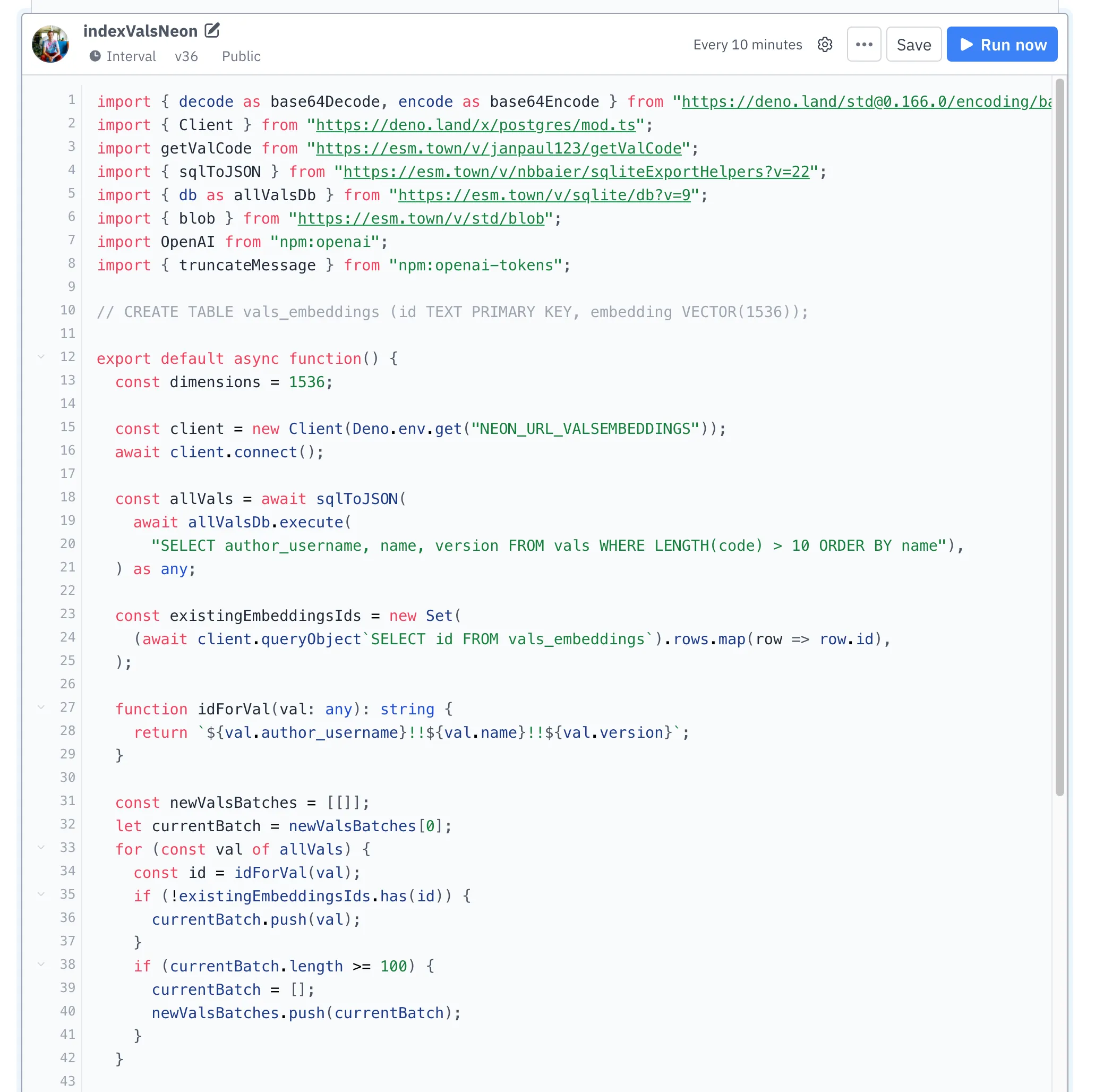
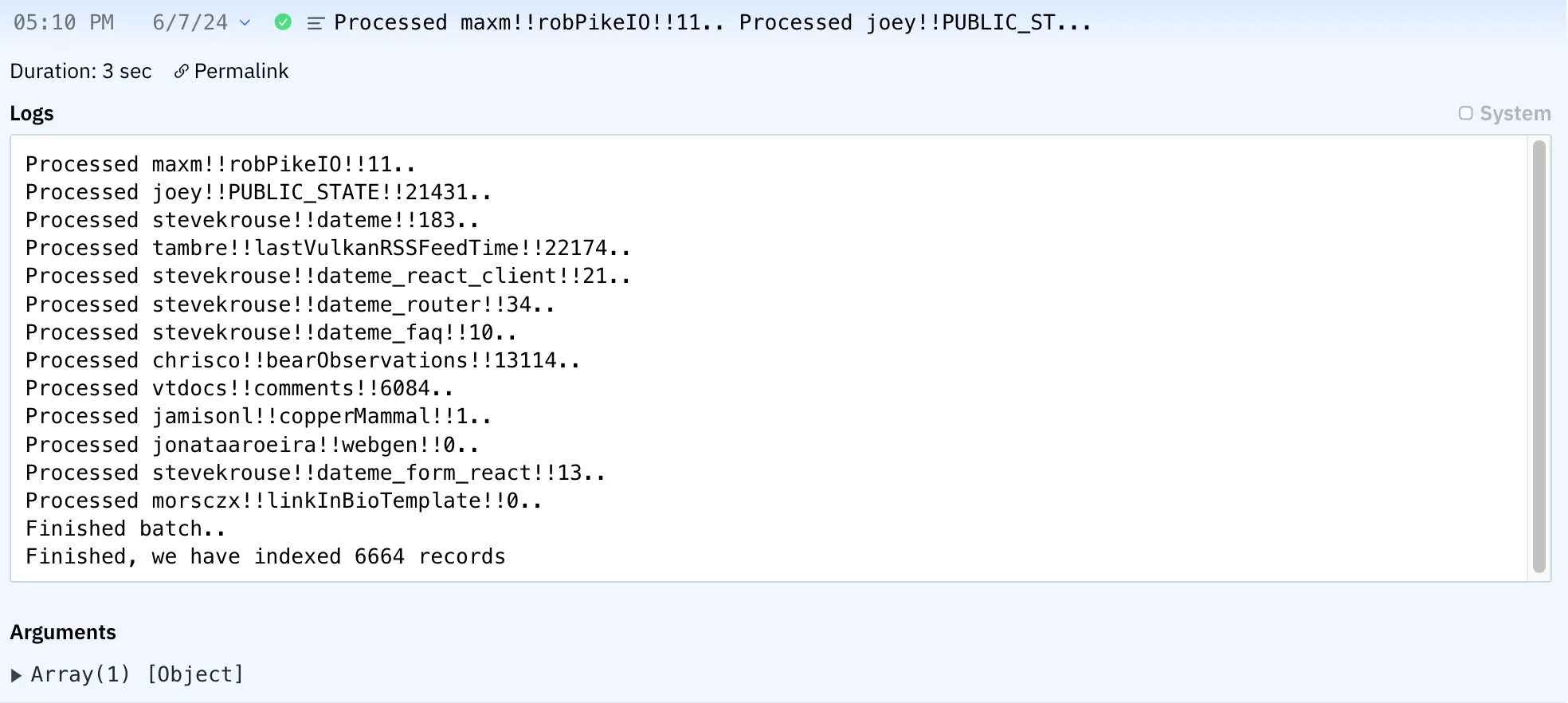
Then we fetch embeddings from OpenAI for each batch of 100 in parallel, and save them to Postgres.
This works! Here are the logs from a recent incremental run:
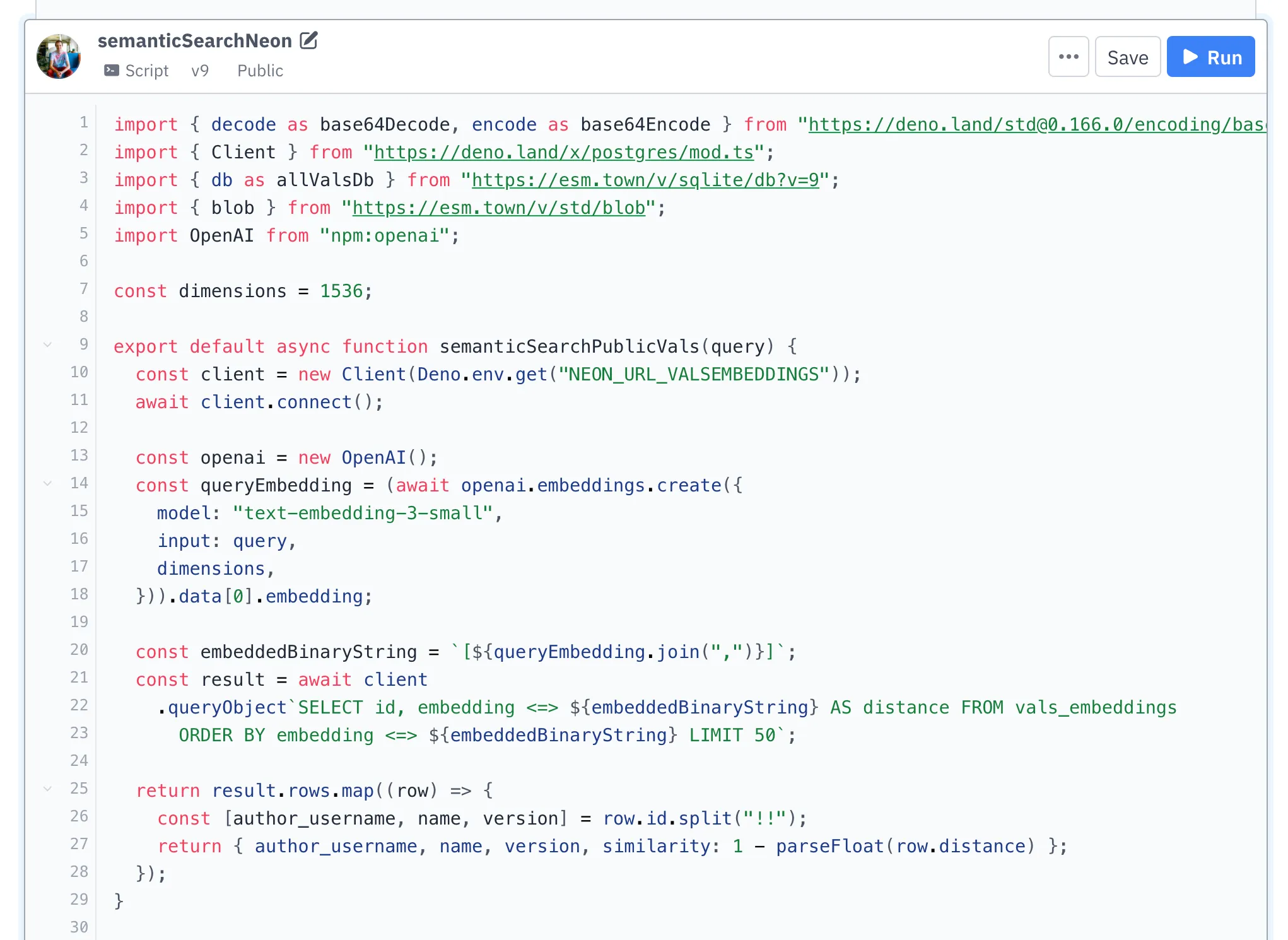
Querying is simpler still. We turn the query string into an embedding, and sort by similarity:
For a nicer UI, I forked an HTTP val (also by Achille Lacoin) and hooked it up to my search function:
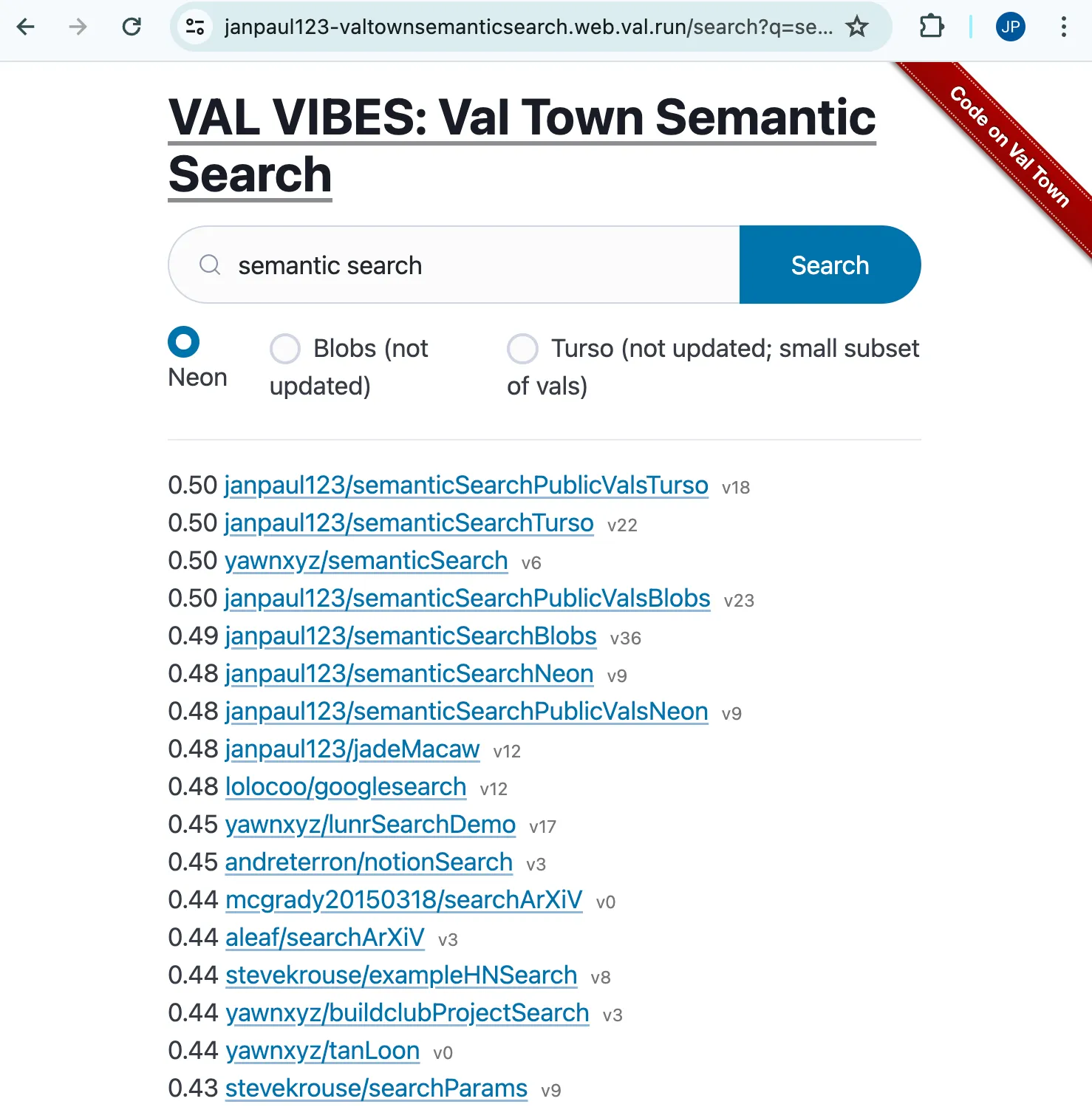
This works pretty well! Check out all my semantic search prototypes here.
Product
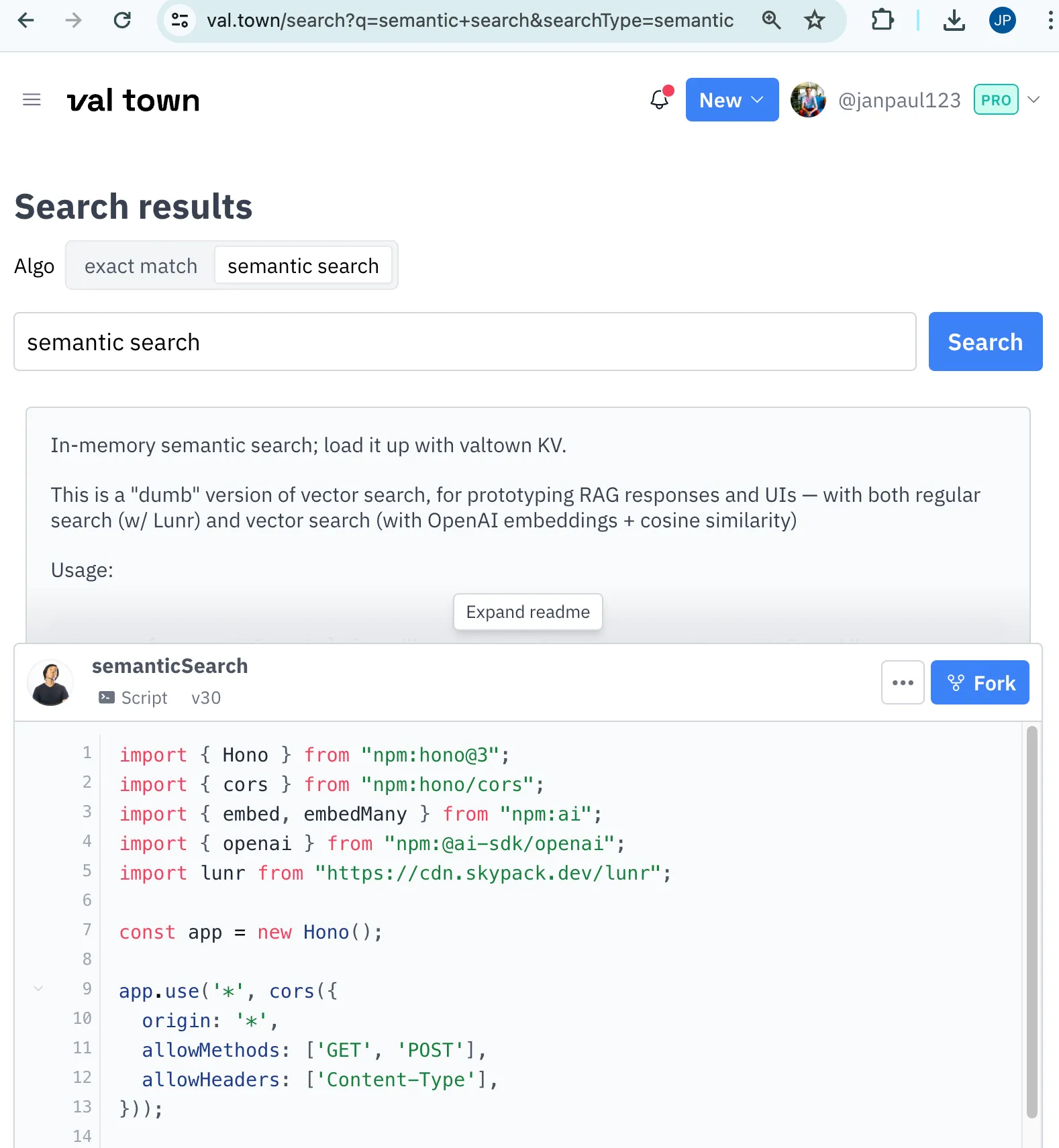
Once the Postgres prototype worked well, I integrated it into Val Town itself. The implementation is roughly the same: I added a pgvector embedding column to our Postgres table that stores vals, and generate an embedding whenever a val is created or updated.
You can use it by going to the search page and selecting “semantic search”.
We’re still iterating on this feature. Here are some ideas we have to improve it, but if you have your own, please let us know on Discord or Github!
- Combine exact and semantic search. Label them differently by highlighting exact matches for exact search, and maybe label semantic results different.
- For searches that return a lot of exact results, improve ranking by using the semantic distance as a ranking feature, in lieu of not having tf-idf stats with our current search setup.
- For both exact and semantic results, add popularity stats (references, forks, likes) as ranking signals. Show all of these in the search results for easier debugging of ranking (currently only likes are shown).
- Do fuzzy search (e.g. levenshtein or similar) in JavaScript, using the top N results from semantic search, to account for misspellings or similar spellings.
- Split exact search on spaces, giving ranking preference to exact phrases and number of parts matching.
Bonus: In-memory
As promised, here is the implementation using in-memory comparisons and blob storage.
This doesn’t require any sort of database, just a place to store bytes. I used Val Town’s standard library, which contains blob storage functions. You can use it to store binary data, or JSON (which gets serialized/deserialized). So we can simply store a blob for every batch of 100 vals, and keep a separate JSON storage to keep track of which embedding is stored where:

Then to query, we load all the blobs in memory, and compare them all against the embedding from the query string. This is of course not as efficient as using an index optimized for this sort of sorting, but not too bad for our (still) small number of vals.

Thanks for reading!

Wat.